
















































Nobody Gets a Bonus for Clean Data

Nobody Gets a Bonus for Clean Data
A field report from the AI-vs-data holy war, written from somewhere near the blast furnace
You’ve seen the meme. Everyone on LinkedIn has seen the meme. It’s the one with the big circle (“People talking about AI”), the smaller circle inside it (“People using AI”), the even smaller circle inside that (“People building AI”), and then, standing off to the side with their arms folded and a smug little look on their face, a tiny group labeled “People fixing their data first.”
The implied moral is delivered with the gravity of a fortune cookie: Before you do AI, fix your data.
And honestly? It’s a great meme. I’ve nodded at it. I’ve probably reposted it. It has the irresistible quality of being technically correct, which is the most dangerous kind of correct, because it lets you feel wise while you do absolutely nothing.
Because here’s the thing nobody puts on the meme: telling a company to fix all its data before starting AI is like telling someone to renovate their entire house before they decide which room they actually want to sit in. Rewire the attic. Re-tile the bathroom nobody uses. Repaint the guest room that exclusively stores Christmas decorations. Then, and only then, may you sit down and read a book.
By the time you’re done, you’ve forgotten why you wanted to read.
The question that ruins every “fix your data first” speech
Somebody in the room always asks it, and it always lands like a dropped wrench:
How do we know which data problems matter before we know what problem we’re trying to solve?
This is the whole ballgame, and the meme has no answer for it. “Fix your data” assumes you already know which data is broken in a way that matters. But a steel plant has tens of thousands of process tags. Decades of history. Sensors, logs, master data, manual interventions scrawled into the margins of operational reality. Which of those are load-bearing for your actual goal, and which are just decades of digital sediment?
You don’t know. You can’t know. Not until you point a real question at the pile and watch what falls over.
Welcome to the AI version of chicken-and-egg. Or, as we experience it in heavy industry: the blast-furnace-and-the-Excel-sheet problem.
What actually happens when you start (a horror story)
Let’s say a plant wants to predict strip breakage. Or shave fuel off the reheating furnace. Or catch a bearing failure before the maintenance lead gets the 2 a.m. phone call that ruins his week and his marriage.
Reasonable goals. Everyone agrees data matters. Everyone nods. And then the first project starts, and it is exactly like opening an ancient tomb. You go in expecting treasure. You come out having learned things. Unexpected things. Things that cannot be unlearned.
You discover that three different systems are recording the same temperature, and they disagree. You find four separate values for the same coil weight, none of which anyone will defend under oath. You find a sensor that, upon investigation, has not been calibrated since roughly the last World Cup, and not the most recent one. You find that the critical setpoint decisions everyone assumed were “in the system” are in fact in a spiral notebook next to the control desk, in handwriting that may or may not belong to someone who still works there.
And then, of course, you find it. The file. The one named:
FINAL_v7_FINAL_USE_THIS_ONE.xlsx
It has a sibling called FINAL_v7_FINAL_USE_THIS_ONE_(2).xlsx. Nobody knows which one is real. Both are, somehow, in production.
Now, here’s the part the data-first crowd gets right, so let me give them their moment.
The data-first camp is also not wrong, and that’s annoying
If your environment is a swamp of missing readings, contradictory logs, duplicated master records, unrecorded manual overrides, and five competing versions of the truth, then no, AI is not going to ride in on a white horse and save you. AI is not sorcery. It is applied statistics wearing a nicer jacket. It runs on top of your operational reality, and if that reality is a lie, the model learns the lie beautifully and confidently and at scale.
No algorithm on Earth can compensate for “oh, that sensor stopped reporting in March and nobody noticed.” Or “operators were quietly overriding the setpoint the whole time and we don’t log that anywhere.” Or the all-time classic, the sentence that has killed more analytics projects than any budget cut:

“The data exists, but it lives in a legacy system that only Bob understood, and Bob retired in 2019.”
Bob is gone. Bob is fishing. Bob does not answer email. The system Bob built hums along in the corner, doing something essential, and the institutional knowledge required to interpret its output left the building with Bob’s coffee mug.
So the data-first people aren’t paranoid. They’ve just been burned. The trouble is, their solution “fix everything first”, quietly assumes a world that does not exist in any steel plant I have ever set foot in.
A quick tour of steel-industry IT, for the uninitiated
Steel plants are, technologically, the most fascinating places on the planet, and I mean that with deep affection and mild fear.
In a single facility you will find genuinely cutting-edge stuff: cloud platforms, modern analytics, AI pilots with their own slide decks. And running directly underneath all of it, holding the whole show up like load-bearing duct tape, you’ll find a twenty-year-old MES, a custom application built by a consultancy that dissolved during a previous decade, an OPC interface held together by optimism, a database nobody is allowed to reboot, and at least one Windows server old enough to legally vote.
Some of these systems have achieved a kind of sacred status. Nobody touches them. Not because they’re good, but because nobody knows what happens if they stop. The classic engineering wisdom, “if it ain’t broke, don’t touch it,” eventually matures, in environments like these, into the more honest:
“Even if it is broke, don’t touch it.”
In a place like this, waiting until every data issue is resolved before you attempt AI is a bit like waiting until the entire plant is fully modernized before you begin continuous improvement. Technically possible. Practically? You and I will both be retired, fishing somewhere next to Bob, and the project will still be in committee.
The biggest lie in the whole debate: “good data”
Can we talk about this phrase? People say “good data” like it’s a settled, universal quantity, like the boiling point of water. As if there’s a lab somewhere that certifies it. There isn’t. Data quality is contextual, and pretending otherwise causes more wasted money than almost anything else in this industry.
The exact same dataset can be, simultaneously:
- Excellent for the monthly report
- Fine for the dashboard the plant manager glances at
- Marginal for predictive analytics
- Completely useless for real-time optimization
Same numbers. Four different verdicts. Quality isn’t a property of the data; it’s a relationship between the data and the question.
Your historian might proudly contain 50,000 tags. Sounds majestic. Then the AI project starts, and you discover that for this particular decision, roughly fifteen of them actually matter. The other 49,985 are along for the ride, eating storage and inflating everyone’s sense of how much “fixing” is even relevant.
So stop asking “Is our data good?” It’s an unanswerable, infinite, bottomless-pit question, and committees love it precisely because it never ends. Ask instead:
“Is our data good enough to improve this specific decision?”
That question is cheap. It’s scoped. It has a finish line. You can answer it in weeks, not fiscal years.
So it’s not AI-first or data-first
The whole debate is framed as two camps glaring at each other across the cafeteria “AI-First” versus “Data-First” and that framing is the actual problem. Both are answers to the wrong question.
The real starting point is neither. It’s business problem first.

Let me put it as bluntly as the meme deserves: nobody has ever received a bonus because data quality improved by 12%. I’ve never seen it happen. I’ve never heard a rumor of it happening. People get bonuses because yield went up. Because fuel consumption came down. Because a line stopped going dark at 2 a.m. Because throughput climbed, or quality complaints dropped, or the thing that used to break stopped breaking.
Data quality is a means. Somewhere along the way it got promoted to an end, and once that happens you get the failure mode every plant secretly knows by heart: everyone agrees data quality is critically important; nobody agrees on which data; so everyone forms a committee; and nothing changes, forever, in a stable equilibrium of universal agreement and zero progress.
The healthier sequence runs like this:
Business problem → AI hypothesis → data assessment → gap identification → targeted data improvement → model refinement → business value.
Notice what didn’t disappear. Data improvement is still right there in the middle. The data-first people get their cleanup. It just happens on purpose, aimed at something, instead of as a heroic open-ended quest with no map and no edges.
How the companies that actually win do it
The plants with AI programs that survive past the pilot deck don’t wait for perfect data. They’ve made peace with the fact that perfect data does not exist in manufacturing and never will. Instead, they run a loop that looks roughly like this:
- Find a high-value business problem. Not “improve data quality.” Something a human gets paid more for fixing.
- Build a focused proof of value. Small, sharp, real.
- Assess data readiness for that problem only. Not the whole historian. The fifteen tags.
- Fix only the data that moves the outcome. Leave the other 49,985 alone for now. They’ll keep.
- Refine the model.
- Scale what works, and let the next problem tell you what to fix next.

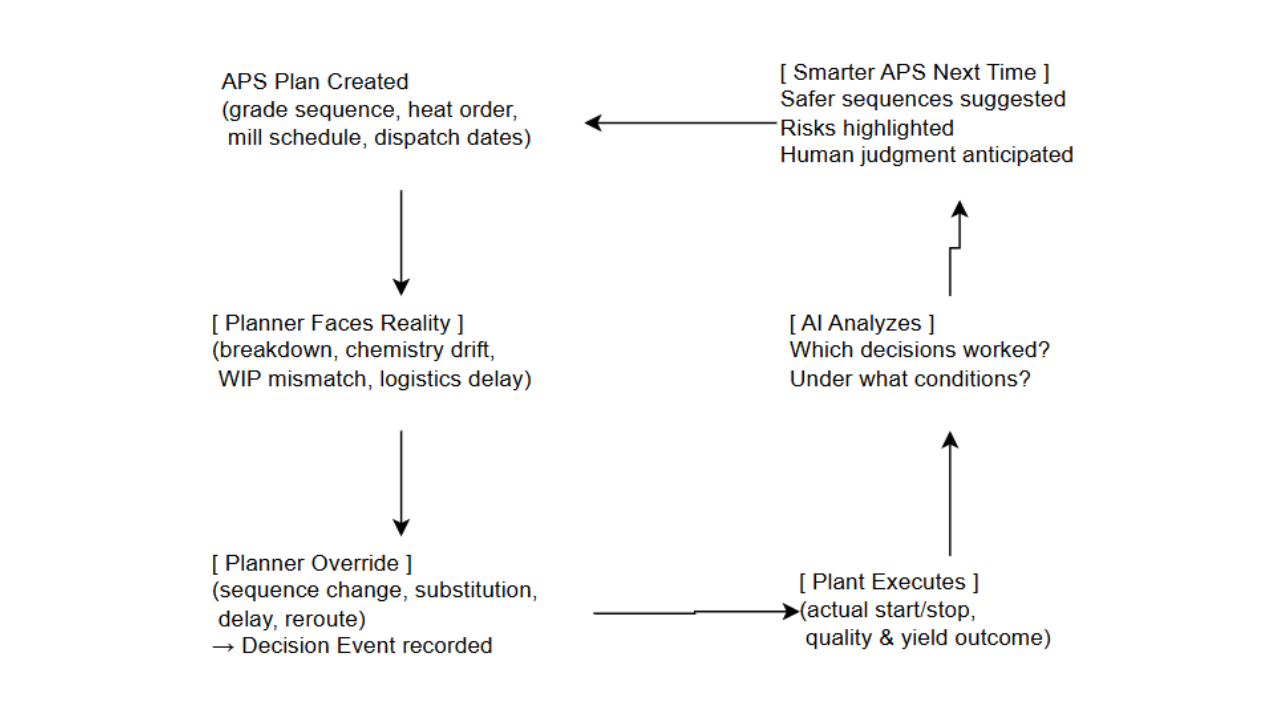
In this version of events, the AI project becomes the thing that reveals what data matters, a catalyst for better data, not a reward you’re only allowed to claim once your data is already immaculate. You learn what’s broken by trying to use it, which is, not coincidentally, how humans learn most things.
The mental model that fits reality isn’t a tidy arrow from Data → AI. It’s a loop where everything feeds everything:
Business Problem ↔ Process Knowledge ↔ Data ↔ AI
Process understanding tells you what should matter. AI surfaces patterns you couldn’t see and surfaces the data problems you didn’t know you had. Fixing those problems strengthens the next model. Business value decides what you tackle next. Round and round. And somewhere in the background, that legacy application from 2004 keeps running exactly as it always has, supremely indifferent to your transformation roadmap.
The part the meme gets right (credit where due)
For all my grumbling, the meme isn’t wrong about the headline. Data matters enormously. You genuinely cannot wave AI at a swamp and expect a swan. Anyone selling you that is selling you something.
But the reality inside most steel companies is messier, funnier, and frankly more interesting than four nested circles can capture. You don’t need perfect data before you start. You also can’t ignore data quality and expect the model to paper over the cracks. The winners live in the tension between those two truths, they use AI projects to discover which data actually matters, fix it deliberately, and keep learning on every lap.
The future doesn’t belong to the AI-first camp. It doesn’t belong to the data-first camp either. It belongs to the organizations that master the feedback loop between business problems, process knowledge, data quality, and AI, the ones who stopped arguing about which came first and just started the loop.
And, perhaps most importantly of all, it belongs to the organizations that finally work out what that mysterious humming server in the corner actually does…
before somebody trips over the cord.
If this resonated, you’ve probably met that server. You may even know its name. Forward this to the one colleague who keeps insisting the data needs to be “ready” first, gently, and with love.
#SteelIndustry #ArtificialIntelligence #DataQuality #DigitalTransformation #ManufacturingAI