
















































I built a clinical tool with AI. Now I'm seeing the steel mill in everything.

Notes from a developer who spent four weeks in someone else’s domain, and is now wondering what that means for his own.
I’m a developer. I don’t know nutrition. I don’t know clinical practice. I’ve never operated a body composition analyzer. I couldn’t tell you the difference between visceral fat and subcutaneous fat without looking it up.
And yet, over four weeks of evenings, I built a clinical-grade consultation tool for nutritionists. Patient management with auto-generated IDs. Body composition tracking with population-specific reference ranges. AI-personalized recommendations that respect drug interactions and dietary restrictions. Multi-language patient handouts in nine Indian languages. Vision-based extraction of legacy paper reports. A whole catalog of products with safety filtering. PDF outputs targeted at three different audiences: clinical referral, the patient themselves, and a transformation report for social sharing.
It’s a real tool. Someone could use it tomorrow in actual practice.
I built it without becoming a nutritionist. The AI I worked with - Claude - didn’t become one either. We were two collaborators who knew nothing about each other’s domains, and somehow, together, we crossed a barrier I would never have crossed alone.
That’s the story I want to tell. But it’s not the most interesting part.
The most interesting part is what happened in my head this morning, when I stepped back and asked: Can I do this for steel?
Because I do know steel. And if the pattern that worked here works there, the implications are big.
The dynamic that surprised me
Before I start mapping parallels, let me explain what actually happened during those four weeks. Because the popular narrative around AI coding is wrong, in both directions.
The hype version says: “AI writes code, developers become 10x productive, anyone can build anything.”
The skeptic version says: “AI hallucinates, produces buggy code, only works for trivial tasks.”
The reality I lived was neither. The AI didn’t replace my thinking, in fact, it amplified it. And it didn’t produce broken code; it produced thoughtful code, often with better defaults than I would have chosen, but it didn’t know what to build. That part was still mine.
The collaboration model that worked looked like this:
I came to the conversation with a fuzzy idea: “I want to build a tool nutritionists can use during patient consultations.” That’s a 12-word brief that hides a thousand decisions. What does a consultation actually look like? What inputs does a nutritionist gather? What outputs do they produce? What’s the legal landscape around clinical advice? What does the workflow look like across multiple visits?
I didn’t know any of this. Neither did the AI, in any deep sense. But the AI was very good at scaffolding the space of decisions I needed to make. It would say things like: “Most consultation tools track per visit measurements with longitudinal trends, do you want to do that or something different?” And I’d say “yes, that” and the conversation would deepen.
What made the collaboration work was that the AI pushed back when I was wrong.
When I asked for a feature to encode an entire patient record into a barcode, the AI didn’t just build it. It walked me through the data realities, a typical patient record runs 8-20 KB, a QR code maxes at 3 KB practical, the math just doesn’t work and proposed three alternatives, each with honest tradeoffs. I ended up choosing none of them. Saying “no” to a feature that doesn’t earn its place is harder than saying yes, and I needed a collaborator who would push back instead of just complying.
When I asked for full mobile-responsive design, the AI laid out the actual use cases honestly: nutritionists rarely edit patient records on a phone, the tool already worked acceptably on tablets, and trying to make an 11-column measurement table elegant on a 380-pixel screen would be hostile UX no matter what we did. I went and tested on a phone. It was fine. I came back and said “no, skip it.” That’s a saved week of work because the AI told me what I didn’t want to hear.
This is the part the hype version misses. The value isn’t that AI codes faster. The value is that AI helps you think faster. The bottleneck in building most software isn’t keystrokes, it’s the unending series of decisions about what the software should be. A good AI collaborator is a thinking partner who’s read more design patterns than you have, knows more failure modes than you do, and won’t get tired of being asked obvious questions.
Three moments that taught me something
I want to share three specific stories from the build, because the abstract framing matters less than what actually happened.
The first was when I added a “load product catalog from a JSON file” feature. Clean code, well-organized, the way I’d build it for a server-based application. I tested it. The catalog wouldn’t load. The error was cryptic: “Failed to fetch.”
I’d hit a browser security restriction I’d genuinely forgotten existed. When you open an HTML file by double-clicking it (the file:// protocol), browsers refuse to let JavaScript fetch sibling files. It’s a sandbox. The error message doesn’t say that it just says “Failed to fetch.”
I told the AI. It immediately recognized the pattern, explained the restriction, and proposed three solutions: embed the JSON inside the HTML so no fetch is needed, run a local web server, or have the user paste the JSON into a textarea. It clearly recommended option one with reasoning: “single-file portability is how everything else in the tool already works.” We went with that. Catalog now embedded, problem gone.
What struck me was the speed of recognition. I would have spent an hour debugging, blamed my code, eventually Googled the error and found it. The AI knew the failure mode instantly because it had seen it many times. This is what domain expertise is, distilled. The AI’s “domain expertise” wasn’t nutrition; it was web platform constraints, software architecture patterns, browser quirks. That expertise was real and consequential.
The second moment was a layout bug in a generated PDF. I sent the AI a screenshot. The patient handout’s disclaimer footer was overlapping the reminders box at the bottom of the page. The AI immediately diagnosed it: the footer was position: absolute, which takes it out of the document flow, so the reminders box above didn’t know to leave room. It proposed the fix, made the change, and also pre-emptively fixed a related issue with the page number that would have hit later.
What I learned from that moment wasn’t about CSS. It was that bugs surface from real use, not from review. The code was reviewed. It “looked right.” The bug only existed in a specific data shape, a patient with a filled distributor strip, pushing content down just enough to expose the overlap. Until I generated a real PDF for a real patient, the bug was invisible.
This is true of all software, but it’s especially true when the requirements come from a domain you don’t deeply understand. You can’t pre-anticipate what will be generated for an actual patient because you don’t know what an actual patient looks like. The only solution is to ship something, test it with real-shaped data, and fix what breaks. The AI is a fast partner for the fix loop. It’s not a substitute for the loop itself.
The third moment was the most interesting. The patient handout PDF was generating in Kannada (a south Indian language) the patient’s preferred language. But when I opened it, half the content was still in English. The static UI labels were translated. The product descriptions, dosing instructions, mechanism notes, all still in English. They came from a catalog file written in English.
This is the kind of issue that surfaces only in production-like use. Reading the code, you wouldn’t notice. The “language” feature was working. The “PDF” feature was working. The bug was at the intersection: a feature that implicitly required catalog content to be multilingual, when nothing in the spec said so.
The fix was non-trivial. We could pre-translate the catalog into nine languages (1,500+ manual translations, frozen content). Or we could translate at PDF generation time using AI (small cost per PDF, scales automatically). I chose option two. The AI built it, a batched translation call with caching, falling back to English on failure, preserving brand names and clinical abbreviations exactly. Cost per PDF: about one rupee. Latency: three seconds.
What struck me wasn’t the engineering; it was that the option to use AI as a runtime translation service didn’t exist meaningfully five years ago. Industrial software has been globally distributed for decades, and the question of “what language do you produce reports in?” has always been answered with painful pre-translation by humans. The economics just shifted. A feature that would have required hiring translators is now a runtime API call costing pennies.
The pivot in my head
So here I am, four weeks in, with a working clinical tool I genuinely couldn’t have built alone. And the developer in me is asking the obvious next question:
if I could do this in a domain I don’t know, what could I do in a domain I do know?

I’ve spent a big chunk of my career in steel industry technology. Mill execution systems. Quality data flows. Production reporting. Customer specification compliance. It’s a domain I have actual fluency in. I know what a mill certificate looks like. I know what a heat treatment log captures. I know why traceability matters when a coil ships to an automotive customer and a defect surfaces six months later.
And as I stepped back from the clinical tool, I started seeing structural parallels everywhere. Let me lay them out.
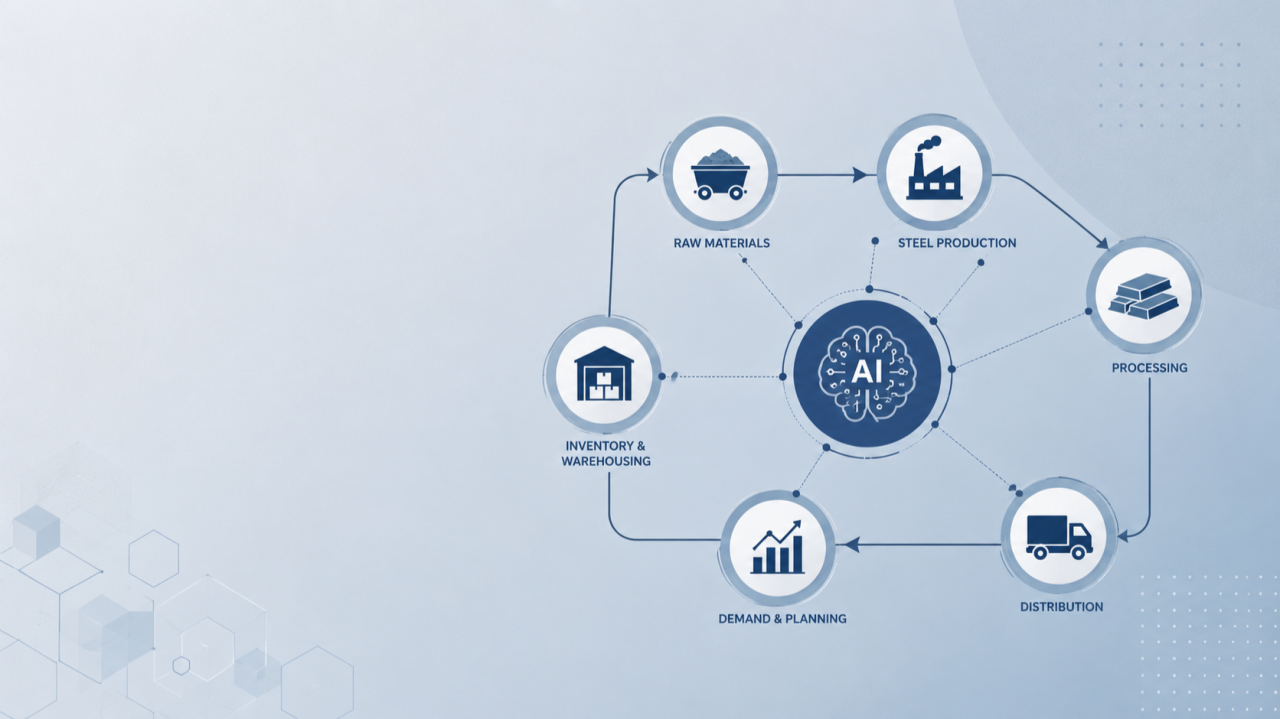
Per-event records with longitudinal tracking. The clinical tool tracks measurements per patient visit. Trends emerge across visits. The steel equivalent: measurements per heat, per coil, per coil-set. Trends emerge across production runs. Same data shape. Same value in seeing the trajectory. Same need for clean per-event annotations (in the clinical case: “knee pain limits walking”; in the steel case: “casting speed reduced 0.2 m/min due to slag carryover”).
Reference ranges by category. Body fat reference ranges differ by sex and age. Tensile strength specifications differ by grade and customer. The data structure is identical: lookup tables of acceptable ranges by classification, flagging when measurements fall outside. The clinical tool’s “Normal / Risky / Very Risky / Extreme” maps directly to “Pass / Caution / Fail” in steel quality. The visualization choices: colored dial gauges showing where you sit relative to the spec, apply just as well to elongation as to BMI.
Safety filtering against context. The clinical tool filters out product recommendations that would be unsafe given a patient’s allergies, medications, pregnancy status, or chronic conditions. A patient on blood thinners doesn’t get omega-3 recommended. The steel parallel: process parameter recommendations that would be metallurgically incompatible with the grade being produced. You can’t recommend a certain carbon range for a grade that’s defined by leanness. You can’t recommend reheat temperatures incompatible with the steel chemistry. The pattern: recommendations filtered through a safety layer derived from context, is the same. Different vocabulary, same architecture.
Vision-based extraction of legacy paper records. I built a feature that takes a photo of any paper BIA report and extracts the values using a vision-language model. Cost: about a rupee per scan. The use case is migrating decades of paper patient records into a database without manual re-entry. The steel parallel writes itself: mill certificates from suppliers arrive as PDFs or scanned documents. Lab test reports. Incoming inspection sheets. Customer specification documents. All of this currently flows through manual data entry in most plants. A vision model can extract structured data from any of it. The economics support it - most plants generate dozens to hundreds of such documents daily, and even at one rupee per document the cost is trivial against the labor saved.
AI-personalized recommendations with safety guardrails. The clinical tool sends the patient’s full profile to an AI, gets back personalized dietary and lifestyle recommendations, and renders them on the report. The same pattern works for process optimization in steel: send the AI the heat chemistry, the target grade, the historical defect data, the customer requirements, and ask for process parameter recommendations. With explicit guardrails about metallurgical safety. The output isn’t the decision - it’s a starting point for the metallurgist to refine. Same role the AI plays for the nutritionist.
Multi-language outputs. I built nine Indian languages for patient handouts because patients across India don’t all read English. The steel mill floor is the same. Operators speak Hindi, Kannada, Marathi, Telugu. Shift handover notes, SOPs, safety bulletins - all of this works better in the native language. The runtime translation pattern (translate at generation time using AI) is just as applicable to a shift report as to a patient handout.
Multi-audience outputs from the same data. The clinical tool generates three different PDFs from the same patient record: a clinical document for the referring doctor, a patient-facing handout in plain language, and a transformation infographic for social sharing. Same underlying data, three audiences, three formats. The steel parallel is direct: the same heat data feeds the internal QC report (dense, technical), the customer mill certificate (regulatory, specification-focused), and the operator dashboard (simplified, action-oriented). Building these as three independent reports is wasteful. Building them as three rendering passes over the same data is elegant. The pattern transferred.
Embedded knowledge bases for offline operation. I embedded the entire product catalog inside the HTML file so the tool works offline. No server. No fetching. The whole thing on a USB stick if you want. Steel plants - especially the ones in remote locations or with poor IT infrastructure - value exactly this. A shop-floor tool that requires constant connectivity to a server is fragile. A tool that runs from a tablet, offline, with the spec library embedded, is robust. The architecture transfers cleanly.
Distributor identity stamping on outputs. The clinical tool stamps the nutritionist’s name and contact on every patient PDF. It’s a brand-presence detail that makes the tool feel like a real practice instrument. The steel parallel: every mill certificate carries the producer’s identity. Every QC report carries the lab’s accreditation. Identity on output is universal in industries where trust and traceability matter.
What I’m taking away

I’m not going to pretend the steel-industry version of this is the same effort as the clinical-industry version. The regulatory landscape is different. The integration with existing systems is different; clinical tools can be standalone; steel tools usually have to talk to Level-2 automation, ERP, MES, and a forest of other systems. The data volumes are different by orders of magnitude. The user base is different (one nutritionist vs. a 200-person shift crew with role-based access).
But the pattern is the same. And the pattern is what I think is interesting.
Here’s what I genuinely believe after these four weeks:
Building software with AI as a collaborator is qualitatively different from building software with AI as a code generator. The first is a thinking partnership. The second is autocomplete. They produce different outcomes. The thinking partnership is what makes domain crossing possible.
Domain barriers are smaller than they look, but not zero. I didn’t become a nutritionist. I built a clinical tool. The trick wasn’t that AI gave me clinical knowledge - it gave me enough scaffolding to ask the right questions of a domain expert. (And in this case the “domain expert” was a hypothetical user I held in my head, informed by research, my own self-care knowledge, and the AI’s pattern recognition. A real engagement would involve an actual nutritionist as co-designer, which would be even better.) The skill that mattered wasn’t domain expertise. It was the ability to recognize when I was making a domain decision that needed grounding.
For industrial software, the economic floor for “AI-assisted features” just dropped through the floor. A rupee per scan. Two rupees per report. These are numbers that change what’s economically feasible. Features that would have required dedicated translators, OCR vendors, or analytical pipelines now require an API call. Industrial plants, including steel plants, have been operating with paper-and-spreadsheet workflows for decades because the build cost of bespoke software exceeded the value. That equation just shifted.
Single-file, offline-capable, lightweight tools are underrated. I built this as one HTML file. It works on file://. It runs on a phone, a tablet, a laptop, a desktop. It works on planes, in basements, in plants with locked-down networks. The dominant architecture of modern software: heavy frameworks, server backends, constant connectivity, is overkill for many real workflows. There’s a whole class of industrial use cases where the right answer is a single file with embedded knowledge and AI for runtime intelligence.
The biggest lesson is about restraint. The most valuable conversations with the AI weren’t when it built things. They were when it said “this isn’t worth building” or “the simpler version is better here.” Software bloat is the default state of long-running projects. An AI collaborator that helps you say no is more valuable than one that helps you say yes faster.
What I don’t yet know
I’m going to be honest about the gaps.
I haven’t built the steel version of this. I’m pattern-matching. There may be load-bearing differences I haven’t seen yet because I haven’t tried. The regulatory environment around steel quality data, especially for safety-critical applications like automotive, may be much harder to navigate than I’m imagining. The integration burden with legacy Level-2 automation may swallow the savings from AI-assisted development.
I also don’t know how this generalizes beyond me. I’m a developer with industry experience and access to a strong AI collaborator. The “anyone can build software” version of this story is overstated. I could build software with this approach. Whether a non-developer in a steel plant could do the same is genuinely uncertain. My guess is they could go further than they think, but not as far as the breathless versions of the story suggest.
And there’s a meta-question I keep circling: what happens to the value of domain expertise when the cost of crossing domains drops? In one reading, domain experts become more valuable because they’re the differentiator. In another reading, domain experts become less defensible because their tacit knowledge gets externalized into tools faster than they can practice it.
I don’t know the answer. I suspect it’s both, depending on the domain.
Closing thought
Four weeks ago, I started this build expecting to learn something about AI-assisted coding. I did. But what I’m taking away is broader.
I’m taking away the conviction that the gap between “I have a problem in my domain” and “I have a working tool for that problem” has narrowed substantially, for anyone willing to think rigorously, push back on their own bad ideas, and treat AI as a collaborator rather than a vending machine.
For industries like steel, with their dense layers of operational complexity, legacy data, and underserved tooling needs, this is a moment worth paying attention to. The tools that get built in the next two years won’t look like the tools of the last twenty. They’ll be lighter, more focused, more AI-native, more willing to make narrow products that do one thing well for one user.
I’m going to try to build one. I’ll let you know how it goes.
If you’ve been thinking the same thing, or you’ve built something in your own domain with AI as your co-pilot, I’d love to hear about it. The interesting examples are the specific ones.
If this post resonated, follow for more notes from building at the intersection of industrial software and AI. I’m trying to write the version of this I wish someone had written for me four weeks ago.
#AI #IndustryFourPointZero #DigitalTransformation #SteelIndustry #BuildingInPublic
Disclaimer: The views expressed in this article are personal in nature, for informational purposes only, and do not constitute professional, operational, or financial advice for specific manufacturing facilities.