











































Five Disciplines - What Good Actually Looks Like
If you have missed out the articles in this series, glance through these for a quick recap:
The Green Dashboard Trap: Why ERP and MES Projects Fail Long Before Anyone Reports Red
What a Steering Committee Actually Is, and Why You Are Using It Wrong
The Trap That Feels Like Safety
Why Scale Changes Everything and Why Your Dashboard Lies at a Different Altitude
The Cascade Nobody Saw Coming
Otherside - The View Nobody Talks About
When the Committee Turns Over and the Programme Pays the Price
Fear Factor — When the Committee Makes Fear the Rational Choice
Eight parts of this series have been spent on what goes wrong.
The Green dashboard that was not Green. The committee that was disarmed by the information it was not given. The relationship that ran out when the sponsors left. The cascade that started with a weighbridge sensor in month ten and ended with a six-month delay and 28% of budget. The incoming committee member who inherited a fiction and made three wrong decisions before she discovered it was a fiction. The governance environment that taught its programme teams to report smoothly by punishing them when they did not.
All of that is real. All of it repeats. All of it is worth understanding precisely because understanding it is the precondition for doing something different.
This part is about what different looks like. Not as an aspiration. As a discipline. A set of specific practices, each with a concrete shape, each grounded in the steel plant implementation context that has been the running backdrop of this series.
Because the most dangerous thing that can happen after eight parts of diagnosis is for the reader to feel that the problems are systemic and the solutions are cultural and therefore nothing she specifically can do will change things.
That is not true. Five things can be done. They can be started on Monday. They do not require the committee to change first. They do not require the organisation’s governance culture to be reformed. They require the programme team to make a set of specific, consistent, unglamorous choices about how information is managed, documented, and surfaced.
What Good Is Not
Before describing what good looks like, it is worth briefly naming what it is not, because the misunderstandings are common enough to be worth addressing directly.
Good reporting is not pessimism. It is not the practice of flagging every minor deviation as a crisis, of turning every workstream RAID log into a catalogue of theoretical risks, of treating every vendor delay as a programme-level emergency. Committees that receive a flood of unfiltered, undifferentiated risk information develop the same governance problem as committees that receive no information: they cannot distinguish what matters from what does not.
Good reporting is not the surrender of the PM’s professional judgment. The PM’s job includes assessing whether a risk is workstream-level or programme-level, whether it requires committee intervention or can be managed within the team, whether the RAG should be Green or Amber. This judgment is part of the role. The problem arises when the judgment is consistently skewed by the incentive to report positively rather than accurately.
Good reporting is not a stream of problems without solutions. The structured escalation, with a problem defined, options mapped, and a specific ask stated, is the format that makes honest reporting useful rather than merely burdensome. A PM who arrives at a steering meeting with a well-formed problem and three options has done her job. A PM who arrives with a vague worry and expects the committee to do the analysis has not.
Good reporting is a discipline. It has a shape. The shape can be learned, practised, and embedded as a programme norm. Five principles describe it.
Principle One: Raise Risks at the Point of Identification, Not the Point of Crisis
The Principle
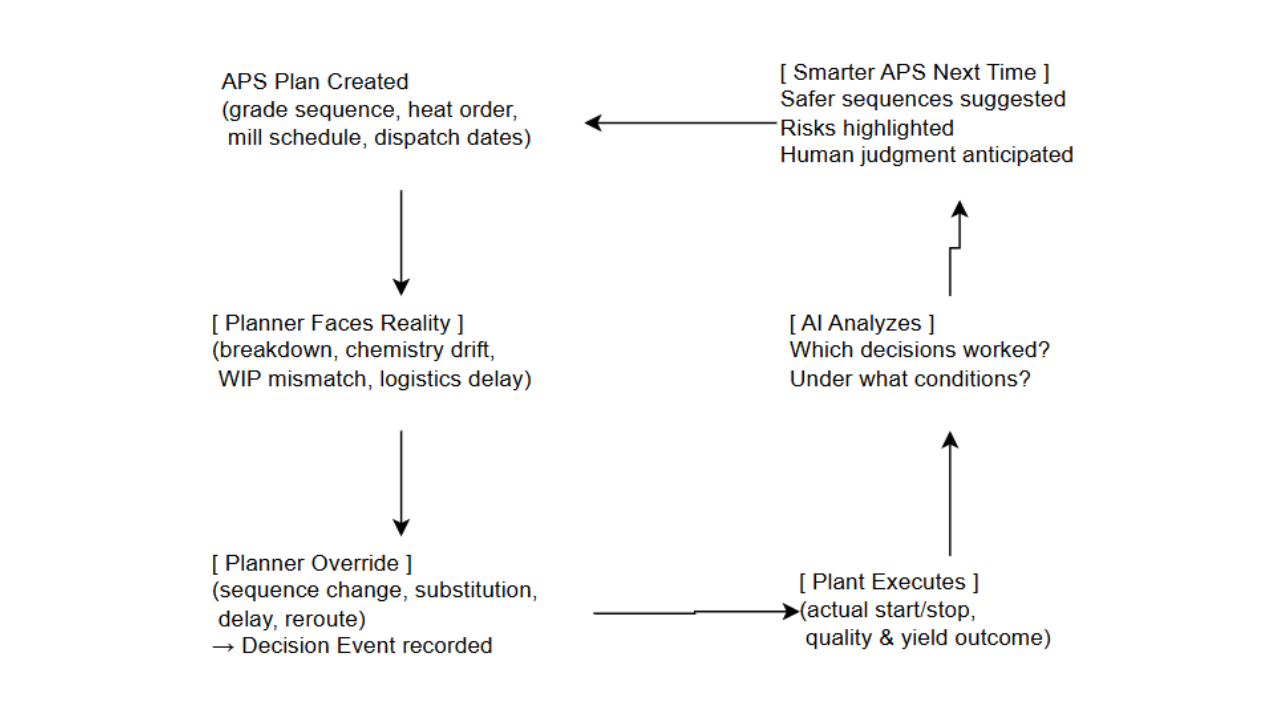
The RAID log is a live document. Not a historical record, not an audit trail, not a filing system for risks that have already been assessed and given a home. A live document that is updated at the moment a risk is identified, at the workstream level, and escalated to the programme level within a defined window for every risk with cross-workstream implications.
The escalation does not require a complete solution. It does not require the PM to have assessed the full impact, identified all the affected workstreams, or designed the remediation approach. It requires three things: a clear description of what has been identified, an honest assessment of what is at risk if it is not addressed, and a statement of what the escalating PM needs from the committee to make progress.
This is not a high bar. It is deliberately not a high bar. Because the bar for escalation, if set too high, will be cleared only by problems that have already grown to the point where the committee’s options are limited. The point of the principle is to surface problems while the options are still wide.
In the Steel Plant Context
The raw material intake workstream lead in the weighbridge sensor example knew in month ten that the sensor accuracy exceeded the threshold in the MES interface specification. She did not know the full impact. She did not know which other workstreams were affected, how the blast furnace scheduling algorithm would respond to the inaccurate data, or what the go-live impact would be.
She did not need to know these things before escalating. She needed to know three things: there is a sensor accuracy issue, it exceeds the threshold in the interface specification for workstream two, and resolving it requires a capital expenditure approval from plant operations.
That is the escalation. Three sentences. Brought to the fortnightly programme review in month ten. The committee, which includes the plant operations director, expedites the capital expenditure approval. The sensors are on order in month eleven. The programme absorbs a planned two-month delay in workstream one rather than an unplanned six-month delay across four workstreams.
The difference between these two outcomes is not the sensor. The sensor was going to fail in both scenarios. The difference is the timing of the information.
A Practical Example: The Coke Plant Data Feed
An integrated steel plant is implementing an APS system for its full production chain. The APS requires a real-time data feed from the coke plant’s production management system to update its constraint model for blast furnace scheduling.
In month eight, the coke plant workstream lead identifies that the coke plant’s production management system does not have an API that the APS integration team can use. The data is available in a legacy reporting database that is updated every four hours, not in real time. The APS’s constraint model was designed around a real-time feed. A four-hourly update cycle will reduce the accuracy of the blast furnace scheduling recommendations by an amount that the APS vendor says is “within acceptable tolerance” but has not quantified.
The workstream lead assesses the situation. She believes the four-hourly update will be adequate. She does not escalate. She logs the item in her workstream RAID register as a technical observation and reports Green.
She does not know that the APS programme architect, who understands the blast furnace scheduling algorithm’s sensitivity to coke quality data, would assess the four-hourly update as inadequate for the grade transition scenarios that represent 30% of the plant’s scheduling complexity. She does not know this because she has not asked him. She has not asked him because escalating would have involved surfacing the issue at the programme level, which she was trying to avoid.
In month fourteen, during APS simulation testing for blast furnace scheduling, the programme architect reviews the simulation results and identifies that the grade transition scenarios are producing suboptimal recommendations. His investigation traces the issue to the four-hourly coke data update cycle.
The remediation requires either a real-time API to be built on the coke plant’s production management system, which is a six-week development task, or a redesign of the APS constraint model to reduce its sensitivity to coke quality update frequency, which is a four-week configuration effort.
Both options were available in month eight. Both options require six weeks maximum in month eight. In month fourteen, they are available at the same technical cost but at a programme cost of four additional weeks of delay to the APS go-live, because the simulation testing window that surfaced the issue is now the critical path.
The four-week remediation in month fourteen costs the programme four weeks of go-live delay. The same four-week remediation in month eight costs the programme nothing, because it could have been planned into the schedule.
The Specific Habit: The Two-Week Escalation Rule
The operational habit that embeds this principle is simple: every risk identified at the workstream level that has potential implications for another workstream’s plan, budget, or timeline is escalated to the programme level within ten working days of identification.
Not when the assessment is complete. Not when the mitigation is designed. Within ten working days of identification, with whatever is known at that point.
The ten-day window is not arbitrary. It is the minimum time needed for the programme-level governance process to receive the escalation, assess its cross-workstream implications, and surface it in the next fortnightly programme review. A risk identified on a Monday and escalated within ten working days will be in the following fortnight’s programme review. A risk that waits until the assessment is complete may wait six weeks, by which time the downstream workstreams have advanced their plans by six weeks against the incorrect assumption.
Principle Two: Map and Track Cross-Workstream Dependencies as Live Programme Infrastructure
The Principle
The interface register, the document that records the data flows and output-to-input dependencies between workstreams, is almost always treated as a design phase artefact. It is created during the blueprint or architecture phase, reviewed and agreed, and then filed. It is referenced occasionally during configuration when interface questions arise. It is dusted off during integration testing when interface failures need to be diagnosed. Between these moments, it sits in the programme’s document library, accurate as of the date it was last updated, increasingly inaccurate as a description of the programme’s current state.
This is the wrong lifecycle for this document. The interface register should be reviewed in every programme-level governance session, not as an administrative exercise but as a substantive governance activity: have any of the dependencies in this register changed since the last review, and if so, what is the downstream impact?
Interface changes are the primary carrier of cross-workstream risk in ERP, MES, and APS programmes. They need to be tracked with the same live discipline as the project plan.
In the Steel Plant Context
A steel plant ERP and MES programme has a richer and more complex interface landscape than most programmes of equivalent budget and timeline. The interfaces are not just software-to-software data exchanges. They are the connection points between physical operational systems, production execution systems, planning systems, and financial systems, each with its own data format, update frequency, accuracy requirement, and business logic dependency.
In a typical steel plant implementation programme, the interfaces include:
The connection between the raw material intake system and the MES, carrying material chemical and physical properties, weighbridge measurements, and stockyard inventory positions.
The connection between the MES and the SAP production order management, carrying production order schedules, actual production confirmations, quality inspection results, and yield data.
The connection between the MES and the APS, carrying real-time constraint updates, equipment status, production progress, and inventory positions that the APS uses to maintain the accuracy of its planning model.
The connection between the MES and the quality management system, carrying inspection results, grade certifications, and non-conformance records.
The connection between the APS and the SAP sales order management, carrying order confirmations, promised delivery dates, and capacity availability information that the sales team uses to commit to customers.
Each of these interfaces has a specification. Each specification was accurate at the time it was written. Each specification changes as the programme develops: as configuration decisions are made, as vendor deliveries shape the data format, as business process decisions affect the data content, and as operational constraints emerge that were not fully understood during the design phase.
A live interface register tracks these changes in real time and surfaces them in the programme governance as cross-workstream risks. A static interface register allows changes to accumulate silently until integration testing reveals the divergence at the worst possible moment.
A Practical Example: The APS-SAP Sales Order Interface
An integrated steel plant is implementing an APS system alongside an ERP upgrade. One of the critical interfaces is between the APS planning engine and the SAP sales order management module. The APS is supposed to provide available-to-promise information to the sales order module, enabling the sales team to commit to delivery dates that are achievable given the plant’s current production plan and constraints.
The interface specification, written in month three of the programme, describes the APS as providing a daily update of available production slots by product group, which the SAP sales order module uses to validate delivery commitments.
In month nine, the APS configuration team makes a significant design decision: the APS will plan at the individual order level rather than the product group level, because the plant’s production complexity makes product-group-level planning insufficiently granular for the constraint optimisation the APS is supposed to provide.
This is the right design decision from an APS planning perspective. It is a significant change to the interface specification from a SAP sales order perspective. The SAP sales order module was configured to receive product-group-level availability data. Receiving order-level availability data requires a different configuration of the available-to-promise logic, a different data mapping in the integration layer, and a different validation process in the sales order entry workflow.
The APS configuration team makes this decision and records it in the APS workstream’s design documentation. They do not update the interface register, because the interface register is a programme-level document that the APS workstream lead does not regularly update. They do not notify the SAP sales order workstream, because the design decision feels internal to the APS and its implications for the interface are not immediately obvious.
The SAP sales order workstream continues its configuration of the available-to-promise logic against the product-group-level specification. The integration team, working from the original interface register, builds the integration layer for product-group-level data.
In month fifteen, the integration testing for the APS-SAP sales order interface reveals that the APS is sending order-level data and the SAP module is expecting product-group-level data. The integration layer does not know how to translate between the two formats because neither format was anticipated in its design.
The remediation involves reconfiguring the available-to-promise logic in the SAP sales order module, rebuilding the integration layer mapping, and retesting the end-to-end flow. It takes six weeks.
If the interface register had been a live governance document, the APS design decision in month nine would have triggered a flag in the next programme review: “The APS planning granularity has changed from product-group to order-level. This changes the interface specification with the SAP sales order module. The SAP workstream and integration team need to assess the impact.” The remediation could have been designed and built alongside the APS configuration change, at no incremental delay to the programme.
The six-week integration testing remediation in month fifteen was the cost of a static interface register.
The Specific Habit: The Interface Change Notification
The operational habit that embeds this principle is a standing expectation on every workstream lead: any configuration or design decision that affects the content, format, frequency, or accuracy of an outgoing interface is notified to the programme director and the affected downstream workstream leads within five working days of the decision being made.
Not when the full impact is understood. Not when the remediation is designed. Within five working days of the decision, with enough information for the downstream workstream lead to understand what has changed and begin her own assessment.
This notification creates the programme-level awareness that the interface register’s static version cannot provide. It makes interface changes visible as programme events rather than workstream-level technical details. And it surfaces cross-workstream dependencies in the moment they are stressed, not in the integration testing window when the stress has already caused damage.
Principle Three: Separate the Problem from the Ask in Every Escalation
The Principle
The structured escalation is the PM’s primary tool for converting honest information into governance action. Without structure, an escalation is a problem presented to a committee that does not know what to do with it. With structure, an escalation is a decision request presented to a committee that has everything it needs to act.
The structure has three components. They are always the same three components, regardless of the nature of the problem.
First: the problem, defined clearly and concisely. What has been identified, when it was identified, what the current trajectory is if nothing changes, and what the potential impact on the programme is in terms of schedule, cost, and scope.
Second: the options, mapped honestly. What can be done within the PM’s own authority, what requires committee-level resource or decision, and what the likely outcome of each option is. Options do not need to be perfect. They need to be real, distinguishable, and honestly assessed.
Third: the specific ask. What decision, approval, or intervention does the PM need from the committee, by what date, and what happens to the programme if the committee does not provide it by that date. Not a general request for support. A specific ask with a specific deadline and a specific consequence.
In the Steel Plant Context
Steel plant implementation programmes are particularly prone to escalations that arrive as problems without asks. The cultural norm of presenting a comprehensive picture before requesting support produces programme reviews in which the committee is given a detailed description of a technical issue and then waits to understand what is being asked of them.
The committee is not in a position to determine on its own what it can usefully do. It needs the PM to tell it. The PM who does not tell it what she needs has not completed the escalation.
A Practical Example: The Hot Strip Mill Scheduling Module
An integrated steel plant is implementing an MES for its hot rolling operations. The hot strip mill scheduling module is responsible for generating the rolling campaign plan: the sequence of coils to be rolled, grouped into campaigns by width and gauge to minimise roll changes and optimise yield.
In month eleven, the MES workstream lead identifies that the rolling campaign optimisation algorithm is not producing feasible schedules for one specific scenario: mixed campaigns containing both automotive-grade and structural-grade coils with similar width and gauge specifications but different surface quality requirements.
The optimisation algorithm is placing automotive and structural coils in the same campaign segment, which violates the plant’s established practice of segregating these grades to avoid surface quality contamination risk. The algorithm does not have this constraint in its configuration, because the constraint was not documented in the original MES functional specification. It existed as an operating practice known to the rolling mill operators but not captured in the design documentation.
The workstream lead brings this to the steering committee. She has prepared a structured escalation.
The problem: the rolling campaign algorithm is not enforcing the automotive-structural grade segregation constraint. This constraint was not in the functional specification. If not addressed, the MES will generate rolling schedules that violate the plant’s quality management requirements for automotive-grade products. The impact on the go-live is a four to six week delay to the scheduling module’s testing completion.
The options: Option one is to add the segregation constraint to the algorithm’s configuration. This is a two-week configuration and testing task within the MES workstream’s own capacity. It delays the module’s testing completion by two weeks. Option two is to add the constraint as a manual override rule in the MES user interface, requiring the rolling planner to apply the segregation manually after the algorithm generates a campaign. This is a one-week configuration task but creates a permanent manual step in the scheduling process. Option three is to raise a formal configuration change request, document the constraint, and assess whether there are other undocumented constraints of similar type that should be identified before the go-live. This is a three-week exercise involving the rolling mill operators and the quality management team.
The ask: the workstream lead is asking the committee to decide between options one and three today, because both require decisions that affect the programme’s testing schedule. Option two is available as a fallback if the committee prefers to protect the testing timeline, but the workstream lead’s recommendation is against it because it creates a permanent operational workaround. If the committee approves option three, she will need the VP of Operations to mandate the rolling mill operators’ availability for the constraint identification exercise, which is outside the workstream’s authority to request directly.
The committee makes the decision in the meeting. Option three is approved. The VP of Operations commits to mandating the operator availability. The constraint identification exercise identifies three additional undocumented operating constraints that would have surfaced as separate issues during testing or post-go-live. All three are configured before testing begins.
The total delay to the testing schedule: three weeks, planned and absorbed. The total number of post-go-live incidents from undocumented constraints: zero.
Compare this to the alternative: the workstream lead patches the specific automotive-structural issue with option two, reports the resolution, and goes live on schedule. The three additional undocumented constraints surface as production incidents in the first month of live operation, each requiring emergency configuration changes in a live production environment, with associated production disruptions and a loss of operator confidence in the MES scheduling system that takes months to rebuild.
The Specific Habit: The Escalation Template
The operational habit that embeds this principle is a standing escalation template that every PM in the programme uses when surfacing a risk to the programme level. The template has three sections and three sections only: Problem, Options, Ask.
The Problem section has a word limit. Not because brevity is always virtuous, but because a PM who can describe the problem in fewer than two hundred words has understood it clearly enough to escalate it. A PM who cannot describe it in fewer than two hundred words may not yet have understood it clearly enough to give the committee what it needs to act.
The Options section requires at least two and no more than four options, each with an honest assessment of cost, schedule, and risk. Not the option the PM prefers presented alongside straw-man alternatives. Genuinely distinguishable options with genuinely different trade-offs.
The Ask section requires a single sentence: “I am asking the committee to [specific decision] by [specific date] because [specific consequence if not provided].”
A programme that uses this template consistently produces escalations that committees can act on. A programme that does not produces escalations that committees have to work to understand before they can act on them, which takes time the committee does not have and produces a reluctance to escalate that the PM learns from experience.
Principle Four: Maintain RAG Discipline as a Programme-Wide Governance Standard
The Principle
The RAG system is the programme’s shared language for status. Its value as a governance instrument depends entirely on the integrity of its inputs. One PM’s optimistic Green does not only mislead the committee about her workstream. It corrupts the aggregate picture that the committee uses to understand the programme as a system, because the programme dashboard is the sum of its workstream inputs, and a sum built on inaccurate inputs is an inaccurate sum.
RAG discipline is not a personal virtue. It is a programme-wide standard. It requires three things: agreed definitions of Green, Amber, and Red at the programme’s inception, consistent application of those definitions across all workstreams, and a programme director who has the authority and the practice of challenging a self-reported RAG when the evidence does not support it.
In the Steel Plant Context
Steel plant implementation programmes have a specific RAG discipline problem that is worth naming separately from the general case.
The plant’s production operations have their own traffic light systems: process alarms, equipment status indicators, quality control charts, safety monitoring systems. The people who lead the business-side engagement in a steel plant ERP or MES programme are accustomed to the idea that a green indicator means the process is within normal operating parameters. It does not mean perfect. It means within tolerance.
This norm transfers, subtly but powerfully, to programme reporting. A Green workstream status comes to mean “within tolerance” rather than “on track.” And “within tolerance” is a significantly more forgiving standard than “on track,” because it allows the PM to absorb a certain degree of deviation before the indicator changes colour.
The result is a dashboard whose Green indicators represent a range of actual programme states: genuinely on track, slightly behind but within what the PM considers manageable deviation, significantly behind but expected to recover, and behind in ways the PM is not yet fully willing to quantify.
The committee receiving this dashboard is reading Green as on track. The PM reporting it is reporting it as within tolerance. They are not speaking the same language, and the gap between those two definitions is where programme risk accumulates.
Agreed, written RAG definitions at programme inception are the solution. Not “Green means good, Amber means concern, Red means crisis.” Specific, measurable, unambiguous definitions:
Green: schedule variance within plus or minus five days of the current baseline on all critical path activities, no unresolved risks with cross-workstream implications older than ten working days, all vendor commitments met in the current reporting period.
Amber: schedule variance between five and fifteen days on any critical path activity, or any unresolved risk with cross-workstream implications between ten and twenty working days old, or one missed vendor commitment with a documented recovery plan.
Red: schedule variance greater than fifteen days on any critical path activity, or any unresolved risk with cross-workstream implications older than twenty working days, or missed vendor commitment without a documented recovery plan, or any issue requiring steering committee intervention to resolve.
These definitions leave no room for the PM’s “within tolerance” interpretation. They are calibrated to the programme’s actual schedule constraints and risk management requirements. They are agreed by the committee at programme inception. And they are applied consistently by every workstream lead in every reporting cycle, with the programme director having the explicit authority to challenge any self-reported RAG that she believes is inconsistent with the evidence.
A Practical Example: The Dashboard That Never Turned Red
A large steel plant ERP implementation has been running for eighteen months. The programme has fourteen workstreams. The consolidated dashboard has shown Green or Amber across all fourteen workstreams for eighteen consecutive months. No workstream has ever turned Red.
The programme director presents the eighteen-month review to the steering committee. The committee chair, who has read this series, asks a simple question: “In eighteen months of a fourteen-workstream programme of this complexity, no workstream has gone Red. Help me understand why.”
The programme director explains that the programme has been well-managed and that risks have been resolved before they reached the Red threshold.
The committee chair asks a follow-up: “Can you show me three specific instances in the last six months where a risk was assessed as approaching Red and was resolved at Amber?”
The programme director reviews her records. She can show two instances where risks were logged as Amber and resolved. She cannot show three instances where risks approached Red and were managed back to Amber, because the risk assessment records do not have this level of granularity.
The committee chair makes a decision: she commissions an independent programme health review, not because she believes the programme is in trouble, but because a dashboard that has never shown Red in eighteen months is not providing the full picture she needs to govern effectively.
The independent review identifies two risks that have been managed at the workstream level and not escalated to the programme level, both of which are, by the agreed RAG definitions, at Red. One is a data migration scope issue that has been absorbing workstream contingency for three months. The other is a vendor resource gap in the integration workstream that has been managed through informal bilateral arrangements with the vendor’s account manager.
Neither risk is catastrophic. Both are manageable with committee intervention. The review gives the committee the information it needs to intervene while the options are still good.
The programme director’s response to the committee chair’s question, two months earlier: “Everything is well-managed, no Red has been needed,” was not dishonest. It reflected the programme director’s genuine assessment. It also reflected an RAG system whose definitions had drifted from the agreed standards and a programme culture in which workstream leads were calibrating their reports to the expectation of Green rather than the reality of the programme.
The Specific Habit: The Quarterly RAG Calibration Session
The operational habit that embeds this principle is a quarterly RAG calibration session, held separately from the fortnightly programme review, in which every workstream lead presents her current RAG rating against the agreed definitions, and the programme director and at least one committee member challenge the ratings against the evidence.
The calibration session is not an accountability exercise. It is a shared governance activity: the programme director, the committee, and the workstream leads working together to ensure that the RAG system is providing the committee with an accurate picture of the programme’s real state.
A programme that runs a quarterly calibration session will find, consistently, that a small number of workstream ratings need to be adjusted when assessed against the definitions rather than the PM’s personal assessment. These adjustments are the most valuable governance intelligence the calibration session produces, because they surface the margin between the programme’s reported state and its real state before that margin becomes a gap and the gap becomes a crisis.
Principle Five: Document Everything That Matters as a Programme Governance Artefact
The Principle
The institutional memory of a programme is not the combined knowledge of the people who are currently working on it. It is the governance record: the change log, the RAID register, the committee decision minutes, the interface register, the escalation notes, the vendor management log.
These documents are not administrative overhead. They are the only account of the programme that survives the people who built it. They are what allows the incoming committee member to understand what has happened. They are what allows the PM to defend her position when a sponsor denies a verbal agreement. They are what allows the programme to be audited, recovered, or handed over without the institutional knowledge walking out of the door with the people who hold it.
The rule is simple: if it mattered enough to decide, it matters enough to document. Every scope change, however small and however informally agreed, gets a change request. Every risk, however preliminary the assessment, gets a RAID entry. Every committee decision gets a minute with a named owner and a completion date. Every vendor commitment gets a written confirmation.
This is not bureaucracy. It is the foundation on which everything else in this section rests. The PM who escalates risks early cannot defend her escalation if the escalation is not in the record. The programme that maintains RAG discipline cannot demonstrate that discipline to an incoming committee member if the RAG history is not documented with the evidence that supported each rating. The committee that makes decisions cannot be held to those decisions if the decisions are not in the minutes with named owners and completion dates.
In the Steel Plant Context
Steel plant ERP and MES programmes have a specific documentation challenge: the plant’s operational culture favours verbal agreements, relationship-based decisions, and local problem-solving over formal process. This culture is efficient for plant operations. It is a governance liability for programme management.
The PM who has been embedded in a steel plant for twelve months has absorbed this culture. She handles scope discussions in corridor conversations because that is how things work in the plant. She manages vendor issues through personal calls to the account manager because that is faster than formal correspondence. She agrees configuration changes with the business process owner over chai because the formal change request process feels disproportionate to the size of the change.
None of these impulses are wrong. All of them need to be followed immediately by documentation.
The corridor conversation about scope needs to be followed by an email that summarises what was discussed, what was agreed, and what the programme impact is, sent the same day, with a request for written confirmation.
The personal call to the vendor account manager needs to be followed by a written summary of the commitments made, sent to the vendor’s PM and the vendor’s account manager, with a read receipt requested.
The chai-and-configuration discussion with the business process owner needs to be followed by a change request, however small, that captures the change, the approver, and the programme impact.
This is not about distrust. It is about building a record that does not depend on the specific people who were in those conversations remaining available, accessible, and consistent in their recollection.
A Practical Example: The Three Chai Conversations
An integrated steel plant is implementing SAP for its maintenance management operations. The project is in its Realise phase. The CMMS workstream lead has a strong working relationship with the plant’s Chief Maintenance Officer, who is the business process owner for the maintenance module.
Over three months, the Chief Maintenance Officer and the CMMS workstream lead have three informal conversations over chai in which the following decisions are made.
The first conversation: the plant does not use SAP’s standard preventive maintenance notification workflow. It uses a modified version that routes high-priority equipment notifications directly to the department head rather than through the normal planning hierarchy. The workstream lead says she will accommodate this in the configuration.
The second conversation: the plant wants the maintenance cost centre assignment to follow the equipment’s current operational assignment, not its home department. This is a non-standard configuration that requires a custom field and a custom validation rule. The workstream lead says she will design and implement this.
The third conversation: the plant wants the spare parts inventory reconciliation to happen weekly rather than monthly, with the reconciliation report going to both the maintenance manager and the finance controller simultaneously. The workstream lead says she will configure the report schedule and the distribution list accordingly.
All three conversations produce real configuration requirements. None of them are documented as change requests. The workstream lead implements all three, because they are real requirements from the legitimate business process owner, and she does not want to create bureaucracy around what she considers normal configuration activity.
In month twenty, the Chief Maintenance Officer retires. His replacement reviews the SAP maintenance module configuration and finds three configurations that are not in the original functional specification and are not documented in any change request record. She asks the programme director why these configurations exist and whether they were formally approved.
The programme director asks the CMMS workstream lead. The workstream lead explains the three chai conversations. The Chief Maintenance Officer who made the decisions is retired and no longer available for confirmation.
The new Chief Maintenance Officer is not sure these are the right configurations for how she wants to run maintenance operations going forward. She has different views on the notification routing and the cost centre assignment. She requests that the configurations be reviewed and potentially changed.
Changing live configuration in an SAP maintenance module that is already in use requires a formal change request, impact assessment, regression testing, and retraining of affected users. What was implemented informally over three chai conversations takes three months to formally review, decide, and change.
Had the three chai conversations been followed by three change requests, two things would have happened. The decisions would have been formally approved by someone with the authority to approve them, which the Chief Maintenance Officer had. And the decisions would have been in the record in a form that the new Chief Maintenance Officer could read and either confirm or challenge through a formal process, rather than discovering them as undocumented configurations that she could not trace to an authorised decision.
The Specific Habit: The Same-Day Documentation Rule
The operational habit that embeds this principle is the same-day documentation rule: any conversation that produces a governance-relevant decision is documented on the same day it occurs.
The format does not need to be a formal document. An email to the decision-maker summarising what was agreed, sent the same day, with a request for written confirmation, is sufficient for most informal conversations. A change request form for any decision that affects scope, budget, or timeline. A minute entry for any decision made in a committee or governance meeting.
The discipline is the same-day timing. Not “I’ll document it when I have a moment.” Not “it’s a small thing, I’ll capture it at the end of the week.” The same day, before the memory fades, before the next conversation happens, before the context that makes the decision intelligible is lost.
A programme team that practices the same-day documentation rule consistently will produce a governance record that is complete, timely, and defensible. A programme team that documents when it is convenient will produce a record that is partial, retrospective, and vulnerable.
The Shape of Good
Five principles. Each with a specific operational habit. Each grounded in the steel plant context with examples that illustrate both what the principle prevents and what it costs when the principle is not followed.
The shape of good is not complicated. It is not exotic. It does not require a new governance framework, a new methodology, or a new set of tools. It requires five habits, practised consistently, every day, by the programme team and supported by a committee that has read Part Eight and understood its responsibilities.
The RAID log is updated at identification, not at resolution. The interface register is reviewed at every programme governance session, not filed at the end of the design phase. Escalations are structured with problem, options, and ask, not presented as problems and left for the committee to figure out. RAG ratings are applied against agreed definitions, not personal assessments of programme health. And every governance-relevant decision is documented the same day it is made, not when convenient.
These five habits, taken together, produce a programme that is not immune to problems. No programme is. They produce a programme that finds its problems early, surfaces them clearly, gives the committee the information and the decision it needs, and absorbs the impact while the options are still good.
That is what good looks like. It is not perfect. It is honest, timely, and structured. In a complex steel plant implementation programme, that is enough.
I will be direct about one thing: I have never seen all five of these habits operating consistently on the same programme at the same time. I have seen programmes that were strong on three and weak on two, and paid the cost of the two. The point is not perfection. The point is knowing which habit you are weakest on and doing something about it before the gap becomes a crisis.
Have you been on a programme that practised all five of these principles consistently? Or been on one where the absence of even one of them produced a cost you did not expect? Tell me which principle is the hardest to maintain in practice, and why. The comments are open.
#ProgrammeGovernance #ProjectManagement #ERPImplementation #MESImplementation #APSImplementation #SteelManufacturing #RiskManagement #HonestLeadership #DeliveryExcellence #IndianManufacturing #SteeringCommittee #ProgrammeDiscipline #StructuredEscalation #RAGDiscipline
Disclaimer: The incidents, characters, projects, and organisations referenced in this article are fictionalised composites drawn from recurring patterns observed across complex transformation programmes. Their purpose is to illustrate leadership and governance lessons rather than describe any specific organisation, project, customer, or implementation. The lessons, however, are very real.